
Le potenzialità del linguaggio Python per l’elaborazione dei dati e per le analisi statistiche sono indiscusse. Ci sono librerie per qualsiasi tipo di analisi e questo consente di avere un set rapido di funzioni utilizzabili.
Python è integrabile con la maggior parte degli strumenti statistici e dei dbms oggi in produzione: R, SPSS, SAS, ma anche Postgresql o Oracle. Python può essere utilizzato per creare una funzione serverless in Amazon Lambda. In particolare vedremo in seguito quanto sia utile quest’ultima possibilità.
Test di normalità
I test per la verifica di un andamento conforme ad una curva di distribuzione Gaussiana.
Shapiro-Wilk Test
Verifica se un campione di dati segue una distribuzione gaussiana.
Assunzioni
Le osservazioni in ciascun campione sono indipendenti ed equamente distribuite.
Codicefrom scipy.stats import shapiro
data = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
stat, p = shapiro(data)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably Gaussian')
else:
print('Probably not Gaussian')
Test K^2 di D’Agostino
Verifica se un campione di dati segue una distribuzione gaussiana.
Assunzioni
Le osservazioni in ciascun campione sono indipendenti ed equamente distribuite.
Codicefrom scipy.stats
import normaltestdata = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.869]
stat, p = normaltest(data)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably Gaussian')
else:
print('Probably not Gaussian')
Test di Anderson-Darling
Verifica se un campione di dati segue una distribuzione gaussiana.
Assunzioni
Le osservazioni in ciascun campione sono indipendenti ed equamente distribuite.
Codicefrom scipy.stats
import normaltestdata = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.869]
result = anderson(data)
print('stat=%.3f' % (result.statistic))
for i in range(len(result.critical_values)):
sl, cv = result.significance_level[i], result.critical_values[i]
if result.statistic < cv:
print('Probably Gaussian at the %.1f%% level' % (sl))
else:
print('Probably not Gaussian at the %.1f%% level' % (sl))
Test di correlazione
I test per la verifica dell’esistenza di una relazione lineare tra due campioni indipendenti.
Coefficiente di correlazione di Pearson
Verifica se due campioni hanno una dipendenza lineare.
Assunzioni
Le osservazioni in ciascun campione sono indipendenti ed equamente distribuite.
Le osservazioni in ciascun campione seguono un andamento normale
Le osservazioni in ciascun campione hanno la stessa varianza
Codicefrom scipy.stats import pearsonr
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [0.353, 3.517, 0.125, -7.545, -0.555, -1.536, 3.350, -1.578, -3.537, -1.579]
stat, p = pearsonr(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably independent')
else:
print('Probably dependent')
Correlazione per ranghi di Spearman
Verifica se due campioni hanno una relazione monotonica.
Assunzioni
Le osservazioni in ciascun campione sono indipendenti ed equamente distribuite.
Le osservazioni in ciascun campione possono essere ordinate.
Codicefrom scipy.stats import spearmanr
data1 = [0.873, 2.817, 0.121, -0.945, -0.055, -1.436, 0.360, -1.478, -1.637, -1.869]
data2 = [0.353, 3.517, 0.125, -7.545, -0.555, -1.536, 3.350, -1.578, -3.537, -1.579]
stat, p = spearmanr(data1, data2)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably independent')
else:
print('Probably dependent')
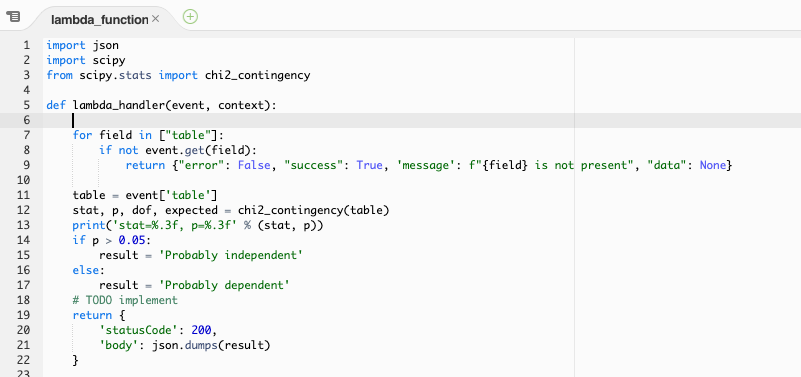
Test del Chi-Quadro
Verifica se due variabili categoriche sono in relazione o indipendenti.
Assunzioni
Le osservzioni utilizzate nel calcolo della contingency table sono indipendenti.
Codicefrom scipy.stats import chi2_contingency
table = [[10, 20, 30],[6, 9, 17]]
stat, p, dof, expected = chi2_contingency(table)
print('stat=%.3f, p=%.3f' % (stat, p))
if p > 0.05:
print('Probably independent')
else:
print('Probably dependent')
Potremmo continuare con la descrizione e l’implementazione di decine di altri test, e lo faremo, ma quanto abbiamo scritto ci aiuta a descrivere un concetto fondamentale: non esiste un solo test di significatività. Siamo abituati a trattare solo un paio di questi test, quelli che di default vengono proposti nei principali programmi statistici o di tabulazione, ma la scelta di un test non può prescindere da una attenta analisi statistica dei campioni.
A partire da questi test è possibile creare delle funzioni che in tempo reale rispondano alle nostre richieste.
Nell’esempio che vi propongo ho creato in Amazon Lambda una funzione serveless legata ad un API Gateway.
In altre parole c’è un URL a cui indirizzare le richieste passando i dati utili per l’analisi.
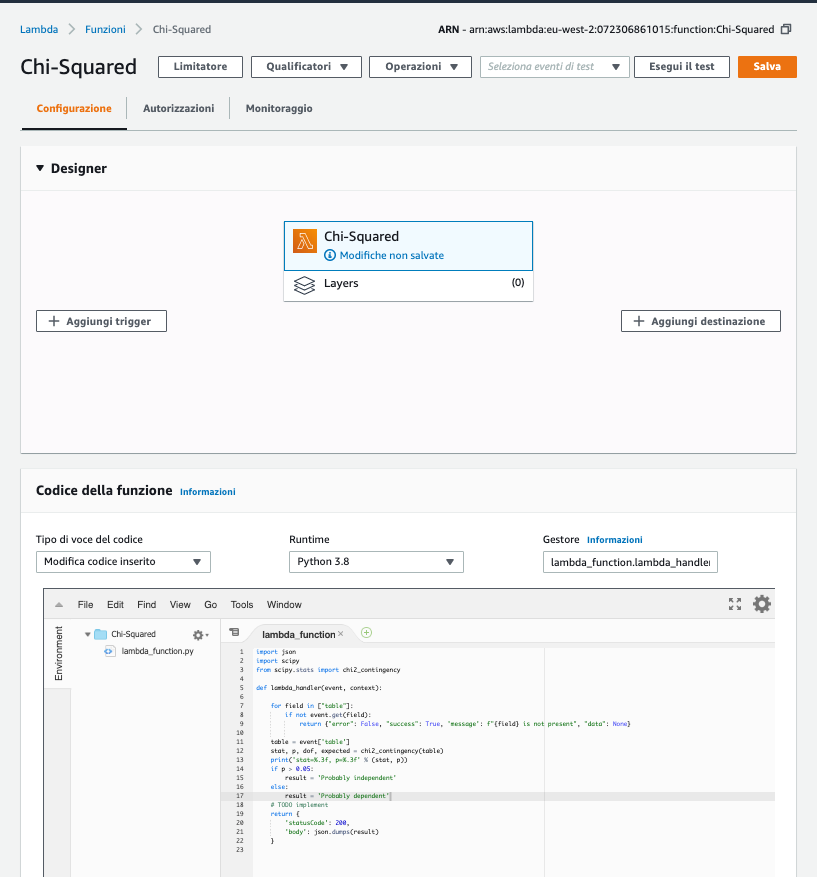
Questa funzione può pertanto essere utilizzata all’interno di dataset personalizzati, consultabili da sistemi di visualizzazione dati, come Amazon QuickSight o Microsoft PowerBI. La funzione personalizzata può essere persino utilizzata per trasformazioni automatiche applicate ai dati mediante sistemi ETL (Extract, Transform, Load).
Le competenze statistiche di un istituto di ricerche di mercato non possono prescindere dalla fruibilità dei modelli su larga scala. Gli ambienti serverless offrono una possibile implementazione sicura e facilmente condivisibile.